
Análisis de datos de WhatsApp con Python
Introducción
WhatsApp se ha convertido en una aplicación de mensajería indispensable tanto para nuestro entorno social como laboral. De ahí que existan publicaciones que orienten como realizar un análisis de los textos que contienen los chats, dado que laboralmente puede ser útil y aprovechable para maximizar ventas, conocer clientes o simplemente por afianzar conocimientos.
En esta primera publicación será con el objetivo de tener las estadísticas del chat y de los autores, incluyendo tablas y graficas. Realizaré otra publicación con el análisis de sentimientos de los mensajes que se envían.
El conjunto de datos que utilicé para crear el código y resultados, es un chat donde estamos seis parejas de amigos y lo utilizamos para conversar y para organizar salidas, viajes, felicitaciones de logros y fechas especiales. Por lo anterior y dada la privacidad de los datos, estos se expondrán de forma anónima y por esta razón no puedo compartir el archivo para replicar los resultados. Sin embargo el código es replicable para realizar sus propios análisis de sus textos en WhatsApp.
Pasos iniciales
Se inicia exportando el chat individual o grupal que se quiera analizar, el cual se guarda en un archivo (txt) en el celular. Con este archivo se procede a implementar nuestro código para extraer, limpiar y separar la información (fechas, hora, autor y mensaje).
El archivo tiene un peso de 2.708 KB y contiene inicialmente 41.439 lineas entre mayo de 2020 y enero de 2022, de los 12 particiapantes (6 hombres y 6 mujeres).
Las librerias que se utilzan son las siguientes;
import os # para indicar la dirección donde se encuentra el chat guardado
import re # expresiones regulares de Python
import regex # expresiones regulares creada particularmente
import pandas as pd # para lectura de los datos
import matplotlib.pyplot as plt # para graficas
import numpy as np
import emoji # para separar los emojis
import datetime # manejo de tiempo y fecha
from datetime import datetime # manejo de tiempo y fecha
from collections import Counter
import plotly.express as px # para graficas
Comenzamos leyendo el archivo del chat, para luego separar, limpiar y extraer las variables que nos interesan.
archivo = 'chat.txt'
df = pd.read_csv(archivo, sep = "delimiter",skip_blank_lines = True, header = None)
splitLane = df[0].str.split(' - ', expand=True) # separa en dos grupos el archivo por guión
splitLane.dropna(subset=[1], inplace=True) # borra las lineas vacias
autor_mes = splitLane[1].str.split(': ', n=1, expand=True)
autor, mensaje = autor_mes[0].copy(), autor_mes[1].copy() #crear variables autor y mensaje
fechas = splitLane[0].str.split(' ', n=1, expand=True)
fecha = fechas[0].copy() # crea la fecha
hora = fechas[1].copy() # crea la hora
chat = []
chat = pd.DataFrame({'fecha': fecha,
'hora': hora,
'autor': autor,
'mensaje': mensaje}) # se crea los nuevos datos limpios y separados
La última línea de código en el cuadro anterior ha creado un nuevo conjunto de datos a partir de las variables extraídas, que luego del proceso de limpieza de datos el conjunto tiene un total de 39.962 líneas.
Ahora se convertirá la variable fecha que está como texto al tipo de variable que pertenece para poder tener un orden cronológico al momento de graficar. también se creará la variable sexo que nos distinguirá los hombres de las mujeres.
chat["fecha"] = pd.to_datetime(chat["fecha"], dayfirst=True)
chat['dia_sem'] = chat["fecha"].dt.weekday
mujeres = ['LF',
'MC',
'JA',
'AG',
'JYA',
'LP'] #variable anonimizada con las mujeres del grupo.
chat['sexo'] = ['F' if x in mujeres else "M" for x in chat['autor']]
La relación entre los participantes hace que sea común que los mensajes contengan emojis, por lo que también tenemos la posibilidad de extraerlos del texto y contabilizar cuales son los más utilizados por el grupo.
# recuento de emojis por medio de extracción en listas
def split_count(text):
emoji_list = []
data = regex.findall(r'\X',text)
for word in data:
if any(char in emoji.UNICODE_EMOJI['en'] for char in word):
emoji_list.append(word)
return emoji_list
chat['emoji'] = chat["mensaje"].apply(split_count) # aplica la función creada
total_emojis_list = list([a for b in chat['emoji'] for a in b])
emoji_dict = dict(Counter(total_emojis_list))
emoji_dict = sorted(emoji_dict.items(), key=lambda x: x[1], reverse=True)
emoji_df = pd.DataFrame(emoji_dict, columns=['emoji', 'count'])
Como último paso antes de realizar los análisis descriptivos, se crean las variables para identificar los mensajes que sean URL, identificar los mensajes que sean imágenes, contar las palabras y letras de los mensajes enviados. Los mensajes que son solo imágenes no pueden ser contados las palabras y letras, por lo cual se modifica para que sean cero.
# identificar enlaces o links compartidos
URLPATTERN = r'(https?://\S+)'
chat['urlcount'] = chat['mensaje'].apply(lambda x: re.findall(URLPATTERN, x)).str.len()
# conteo de palabras y letars en mensajes
chat['conteo_letras'] = chat['mensaje'].apply(lambda s : len(s))
chat['conteo_palabras'] = chat['mensaje'].apply(lambda s : len(s.split(' ')))
# identificar mensajes con multimedia o imagenes
chat['multimedia'] = [1 if x == '<Multimedia omitido>' else 0 for x in chat['mensaje']]
# se reemplazan por 0 en el conteo de letras y palalabras si era mensaje multimedia
chat['conteo_letras'].loc[chat['multimedia'] >= 1] = 0
chat['conteo_palabras'].loc[chat['multimedia'] >= 1] = 0
Análisis descriptivo
Ahora vamos a resumir en una tabla que nos permita conocer la participación de los autores y la agrupación mediante las variables creadas.
resultado = pd.pivot_table(chat,
index=(['autor', 'sexo']),
values=(['mensaje',
'conteo_letras',
'conteo_palabras',
'urlcount',
'multimedia']),
aggfunc=({'mensaje': 'count',
'conteo_letras': 'sum',
'conteo_palabras': 'sum',
'urlcount': 'sum',
'multimedia': 'sum'})
)
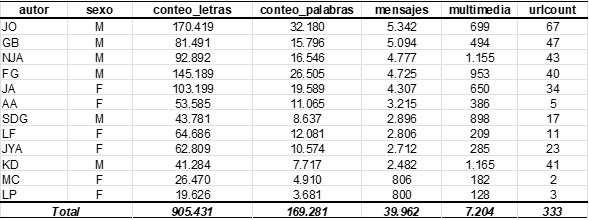
En este ejercicio los resultados de la tabla 1 nos indica que somos los hombres los que más escribimos en el grupo y que algunos participantes tienen menor cantidad de mensajes enviados pero con mayor número de palabras y letras que otros (extensos).
Resumen tabla 1
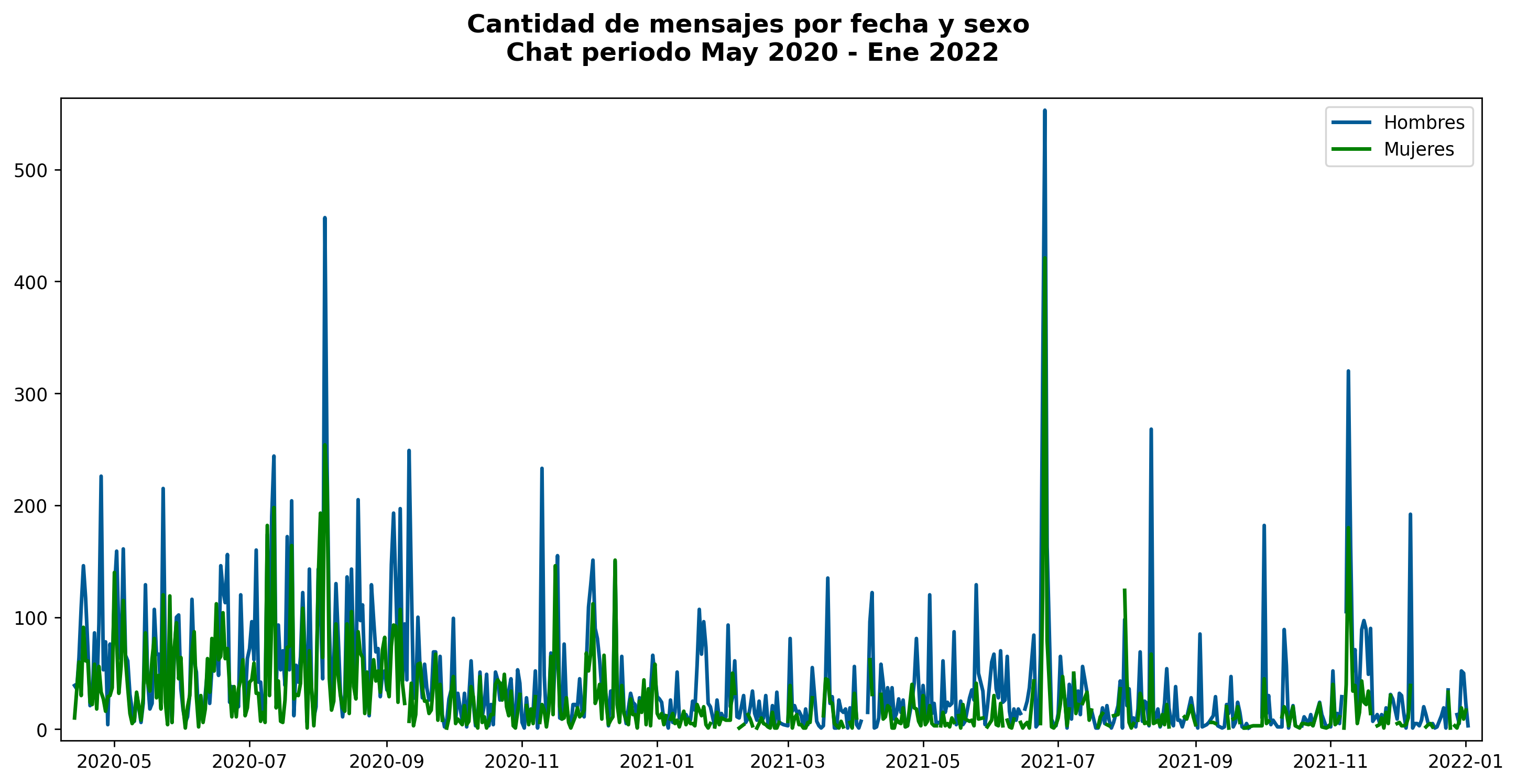
Teniendo el conjunto de datos organizados por fecha, vamos a resumir y generar un gráfico mediante el siguiente código, que nos muestre la actividad del grupo a través del tiempo.
# mensajes por fecha y sexo
mensajes_fecha = pd.crosstab(chat['fecha'],
chat['sexo'],
values=chat['mensaje'],
aggfunc='count'
)
## gráfico 1 - mensajes por fecha y sexo
X = mensajes_fecha.index
YM = mensajes_fecha['M'].copy()
YF = mensajes_fecha['F'].copy()
fig, ax = plt.subplots(figsize=(14, 6.5), dpi=250)
fig.suptitle('Cantidad de mensajes por fecha y sexo\n Chat periodo May 2020 - Ene 2022', weight='bold', fontsize=14)
ax1 = plt.plot(X, YM, color='#005b96', label='Hombres', linewidth=2)
ax2 = plt.plot(X, YF, color='g', label='Mujeres', linewidth=2)
ax.margins(x=0.01, y=0.02) # quita los margenes (espacios blancos) de los ejes
ax.legend(loc='upper right')
plt.show()
El gráfico mediante una forma visual las fechas y sexo que son más activos en el grupo. El eje Y muestra la cantidad de mensajes en la misma linea de tiempo.
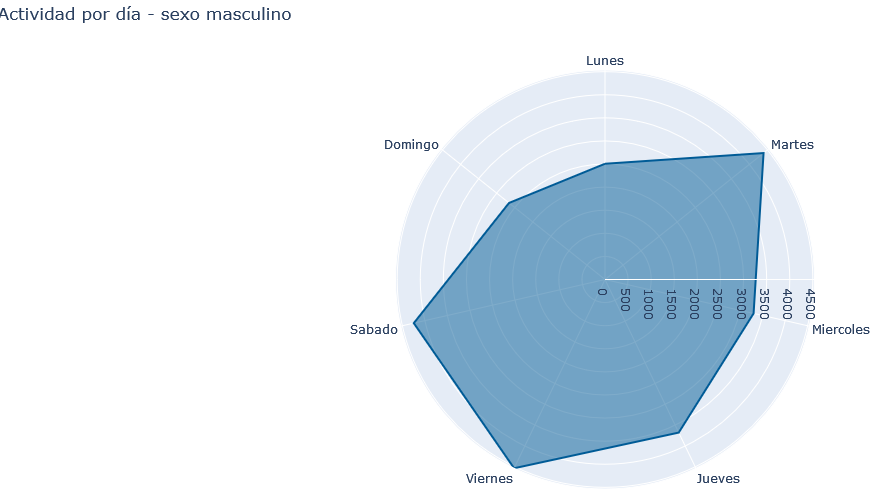
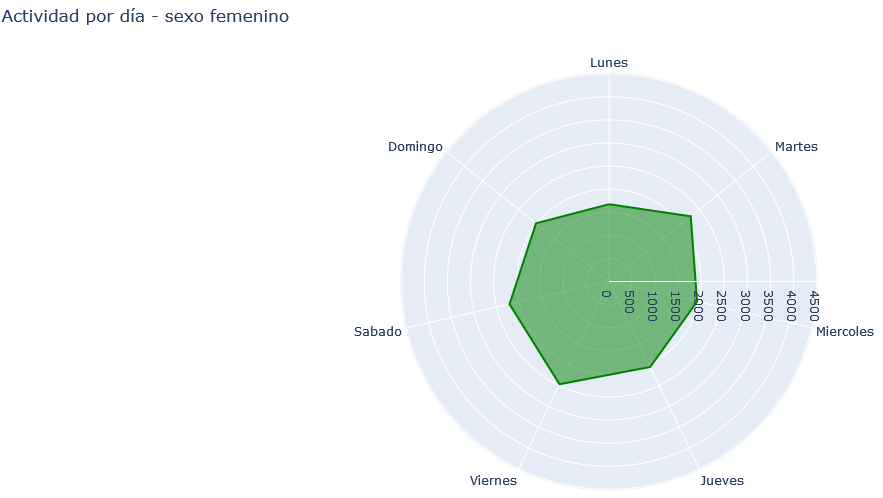
Se puede complementar el análisis del chat por la actividad respecto al día de la semana y el sexo, mediante el siguiente código.
mensajes_dia = pd.crosstab(chat['dia_sem'],
chat['sexo'],
values=chat['mensaje'],
aggfunc='count'
)
mensajes_dia['dia'] = ['Lunes',
'Martes',
'Miercoles',
'Jueves',
'Viernes',
'Sabado',
'Domingo']
fig = px.line_polar(mensajes_dia, r='M', theta='dia',
line_close=True,
color_discrete_sequence=['#005b96']*len(mensajes_dia),
title='Actividad por día - sexo masculino')
fig.update_traces(fill='toself')
fig.update_layout(
polar=dict(
radialaxis=dict(
visible=True,
range=[0, max(mensajes_dia['M'])] # adjust this for better resolution depending on how much the group is used
)),
showlegend=False)
plot(fig)
fig2 = px.line_polar(mensajes_dia, r='F', theta='dia',
line_close=True,
color_discrete_sequence=['green']*len(mensajes_dia),
title='Actividad por día - sexo femenino')
fig2.update_traces(fill='toself')
fig2.update_layout(
polar=dict(
radialaxis=dict(
visible=True,
range=[0, max(mensajes_dia['M'])]
De esa forma también se han creado dos graficas nuevas que resumen la actividad, tomando como referencia el rango mayor en los ejes para poder apreciar las diferencias en la cantidad. El chat grupal tiene un contexto de amistad y tiene sentido que los días con más actividad sean los fines de semana, sin embargo una gran cantidad de menajes enviados el martes, lo que corresponde a la organización de un viaje (selección de hospedaje, compra de tiquetes…etc).
Conclusión
El análisis termina aquí, en el que puedo resumir este ejercicio como una forma divertida de practicar y adquirir algunas habilidades en Python. A nivel personal fue muy interesante pensar en algunos de los hallazgos y discutirlos con los participantes del chat. Desde mi perspectiva la actividad es un ejercicio que consolida lo que comúnmente se hacen en los análisis de datos, encontrando la forma en como visualizar la variedad de hallazgos y con diferentes herramientas. Te recomiendo que pruebes esto por ti mismo y espero que haya sido de utilidad.